The opioid crisis in America was declared a public health emergency on October 26, 2017. The number of opioid overdose deaths continue to climb and with numbers on the rise, there is a need to improve treatments and interventions. Reddit is a network of communities, called subreddits, where groups of people can gather and communicate anonymously. Exploring subreddits dedicated to opioids can provide insights into the social workings of opioid users. This project aims to get a deeper understanding of opioid users by analyzing the words used in two subreddits: r/Opiates and r/OpiatesRecovery. These two subreddits were chosen in the interest of comparison. The goal is to identify any measurable differences between the posts during opioid use and the posts after opioid use. If there are any differences, can these differences help improve treatments and interventions?
In order to collect posts that fell into the timespan of January 1, 2019 - May 31, 2021, pushshift.io API and Python Reddit API Wrapper (PRAW) were utilized. Pushshift.io allows for certain parameters to be scraped from historical data; these parameters include the post ID, the date the post was created, the author of the post, and the number of comments attached to the post, but does not include the body of the post. To extract the body of the posts, the post IDs collected via pushshift.io were looped through PRAW and PRAW used the IDs to search through Reddit, find the posts of interest, and scrape the body of these posts.
Before beginning any analysis, the datasets needed to be pre-processed. First, any rows that contained a null value in the body column were removed. After removing these rows, the Opiates dataset consists of 31,815 posts by 13,045 unique users and the Recovery dataset consists of 10,266 posts by 4,596 unique users. Second, the date was converted from UNIX format to date/time format. Third, the body of the posts were cleaned. The cleaning process involved the following steps: remove URLs, remove special characters and numbers, fix instances where a character appears consecutively three or more times in a single word ('aaaaaah' transforms into 'aah'), expand contractions, and remove common words. We chose to skip lemmatizing to preserve tenses.
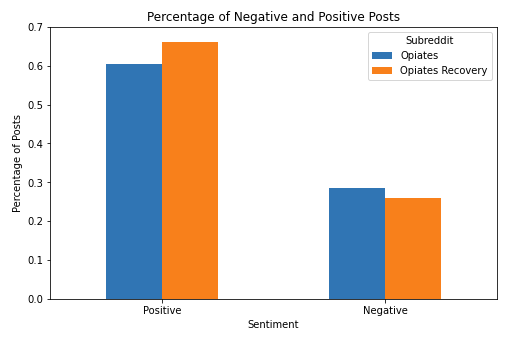
A sentiment classifier was built by training a Linear SVC model with a prelabeled dataset. The trained model assigned a label to each post: -1 for negative sentiment, 0 for neutral sentiment, and 1 for positive sentiment; these labels were used to calculate the overall sentiment for each subreddit. The percentage of posts that were positive and the percentage of posts that were negative are displayed in the first plot below. Overall, Recovery has a higher percentage of positive posts while Opiates has a higher percentage of negative posts.
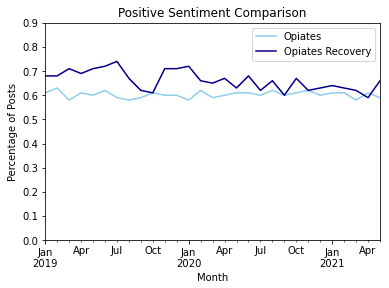
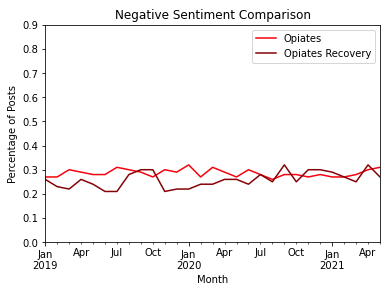
The next two plots allow us to examine a monthly breakdown and identify any changes throughout the time period of the dataset. Plotting the monthly sentiment exhibits that Recovery almost always holds a higher percentage of positive posts and Opiates holds a higher percentage of negative posts up until July 2020. At this point, the percentage of negative sentiment from both subreddits meet. Although the COVID pandemic is not a focus for this project, t-tests were performed on the sentiment pre-quarantine and post-quarantine, with the cut off month being March 2020. There was a statistically significant difference in the negative sentiment and positive sentiment for Recovery (positive sentiment dropped and negative sentiment increased) but there was no significant change in the sentiment of Opiates.
The word networks for the entire datasets were complex which made it difficult to form any conclusions. An example of a word network created for Opiates can be found here and an example of a word network created for Recovery can be found here. To arrive at more meaningful outcomes, part of speech tagging was utilized to build word networks that consist of only adjectives, nouns, or verbs. In an attempt to make the word networks even simpler, graphs for words that are prominent in both datasets, such as "today" and "heroin", were created and compared to see how the contexts differ.
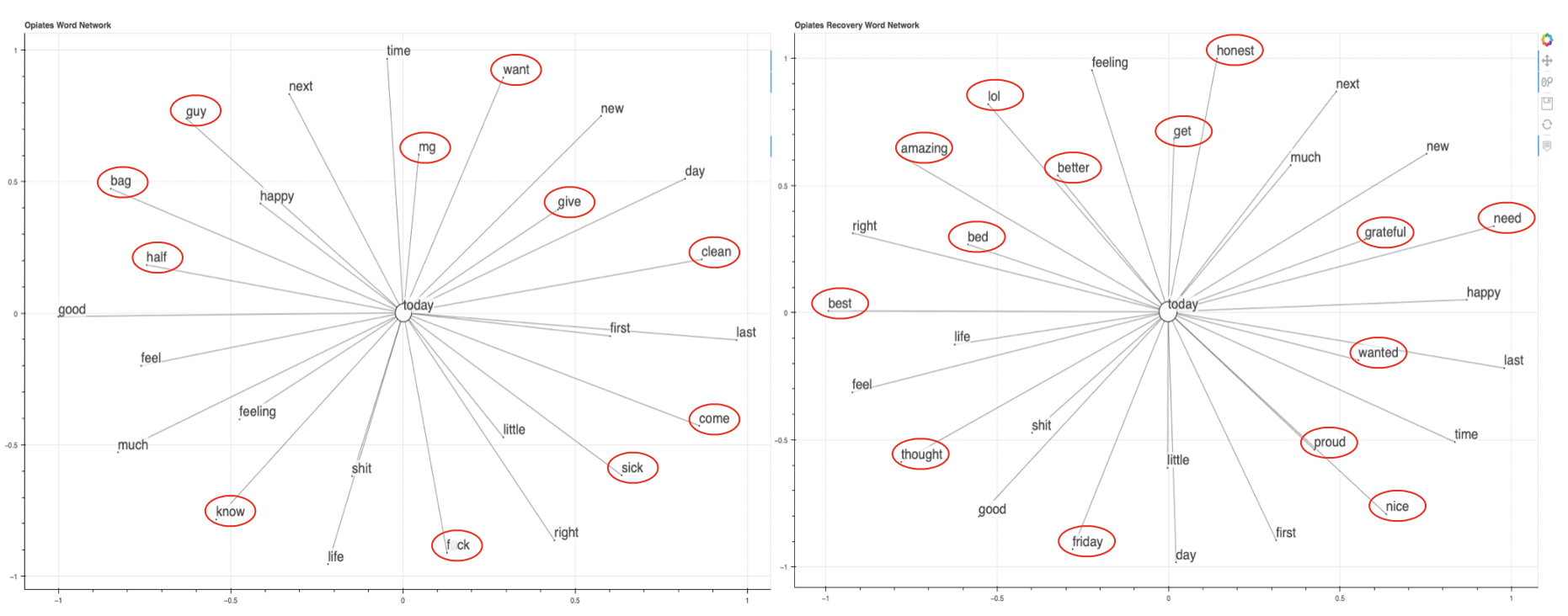
Above we have the word networks of the word "today". The network on the left was created from the Opiates dataset and the network on the right was created from the Recovery dataset. The words surrounded by a red circle are the words that can only be found in the respective network. The difference in the words unique to each subreddit is immediately apparent. There is a higher sense of positivity in Recovery with the words "amazing", "better", "best", "proud", "nice", and "grateful" appearing.
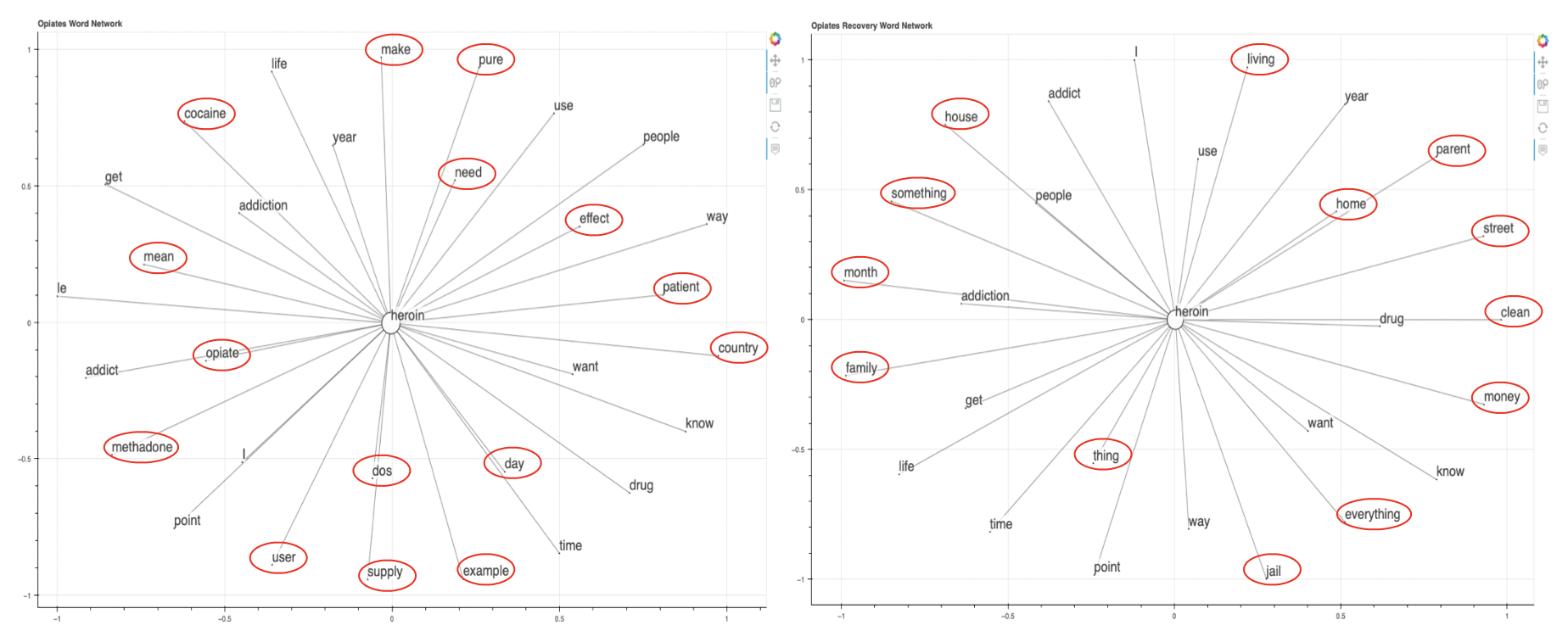
Below we have the word networks of the word "heroin". Just as before, the network on the left was created from the Opiates dataset and the network on the right was created from the Recovery dataset. Again, there is a stark difference in the words that correlate with "heroin". In Opiates, the unique words are all referring to other drugs. In Recovery, we see there is a connection to "family", "parents", "home", and "living"; in general, there are other concerns being discussed in Recovery that may be more important than using.
Below are the interactive visualizations for topic modeling via Latent Dirichlet Allocation (LDA). (Here is a link that provides information on LDA.) On the left hand side of these visuals, the size of the bubbles tells us the percentage of all tokens, or all words, that the bubble represents. Clicking on a bubble allows further examination of a topic. On the right hand side, we have the top 30 most relevant words for the selected topic. The bars next to the words tell us that count of the word in the topic (red) and in the entire dataset (red + blue). The following interpretation of the results of topic modeling was done at a relevance metric of 0.2.